Updated: January 4th, 2009
Here are some quick links for now: http://blogs.mysql.com/kaj/2008/05/23/mysql-clusters-improved-release-model/, http://johanandersson.blogspot.com/2008/05/mysql-cluster-62-officially-released.html, http://blogs.sun.com/theaquarium/entry/improved_release_model_for_mysql.
This article contains my notes and detailed instructions on setting up a MySQL cluster. After reading it, you should have a good understanding of what a MySQL cluster is capable of, how and why it works, and how to set one of these bad boys up. Note that I'm primarily a developer, with an interest in systems administration but I think that every developer should be able to understand and set up a MySQL cluster, at least to make the dev environment more robust.
- In short, a MySQL cluster allows a user to set up a MySQL database shared between a number of machines. Here are some benefits:
- High availability. If one or some of the machines go down, the cluster will stay up, as long as there is at least one copy of all data still present. The more redundant copies of data there are, the more machines you can afford to lose.
- Scalability. Distributed architecture allows for load balancing. If your MySQL database is getting hit with lots of queries, consider setting up a cluster to spread this load in almost linear fashion. A 4 node cluster should be able to handle twice as many queries as a 2 node cluster.
- Online backups.
- Full support for transactions.
- Must-have manual: MySQL Clustering by Alex Davies and Harrison Fisk, MySQL Press.
- First and foremost, I would like to get this out of the way (from MySQL Clustering):
- Response time with MySQL Cluster is quite commonly worse than it is with the traditional setup. Yes, response time is quite commonly worse with clustering than with a normal system. If you consider the architecture of MySQL Cluster, this will begin to make more sense.
- When you do a query with a cluster, it has to first go to the MySQL server, and then it goes to storage nodes and sends the data back the same way. When you do a query on a normal system, all access is done within the MySQL server itself. It is clearly faster to access local resources than to read the same thing across a network. Response time is very much dependant on network latency because of the extra network traffic. Some queries may be faster than others due to the parallel scanning that is possible, but you cannot expect all queries to have a better response time.
- So if the response time is worse, why would you use a cluster? First, response time isn't normally very important. For the vast majority of applications, 10ms versus 15ms isn't considered a big difference.
- Where MySQL Cluster shines is in relation to the other two metrics: throughput and scalability.
- A typical MySQL cluster setup involves 3 components in at least this configuration:
- 1 management (ndb_mgmd) node.
- Management nodes contain the cluster configuration.
- A management node is only needed to connect new storage and query nodes to the cluster and do some arbitration.
- Existing storage and query nodes continue to operate normally if the management node goes down.
- Therefore, it's relatively safe to have only 1 management node running on a very low spec machine (configuring 2 management nodes is possible but is slightly more complex and less dynamic).
- Interfacing with a management node is done via an ndb_mgm utility.
- Management nodes are configured using config.ini.
- My setup here involves 1 management node.
- 2 storage (ndbd) nodes.
- You do not interface directly with those nodes, instead you go through SQL nodes, described next.
- It is possible to have more storage nodes than SQL nodes.
- It is possible to host storage nodes on the same machines as SQL nodes.
- It is possible, although not recommended, to host storage nodes on the same machines as management nodes.
- Storage nodes will split up the data between themselves automatically. For example, if you want to store each row on 2 machines for redundancy (NoOfReplicas=2) and you have 6 storage nodes, your data is going to be split up into 3 distinct non-intersecting chunks, called node groups.
- Given a correctly formulated query, it is possible to make MySQL scan all 3 chunks in parallel, thus returning the result set quicker.
- Node groups are formed implicitly, meaning you cannot assign a storage node to a specific node group. What you can do, however, is manipulate the IDs of the nodes in such a way that the servers you want will get assigned to the node groups you want. The nodes having consecutive IDs get assigned to the same node group until there are NoOfReplicas nodes in a node group, at which point a node group starts.
- Storage nodes are configured using /etc/my.cnf. They are also affected by settings in config.ini on the management node.
- My setup here involves 4 storage nodes.
- 2 query (SQL) nodes.
- SQL nodes are regular mysqld processes that access data in the cluster. You guessed it right – the data sits in storage nodes, and SQL nodes just serve as gateways to them.
- Your application will connect to these SQL node IPs and will have no knowledge of storage nodes.
- It is possible to have more SQL nodes than storage nodes.
- It is possible to host SQL nodes on the same machines as storage nodes.
- It is possible, although not recommended, to host SQL nodes on the same machines as management nodes.
- SQL nodes are configured using /etc/my.cnf. They are also affected by settings in config.ini on the management node.
- My setup here involves 4 SQL nodes.
- 1 management (ndb_mgmd) node.
- Normally a cluster doesn't want to start if not all the storage nodes are connected (from MySQL Clustering).
- Therefore, the cluster waits longer during the restart if the nodes aren't all connected so that the other storage nodes can connect. This period of time is specified in the setting StartPartialTimeout, which defaults to 30 seconds. If at the end of 30 seconds, a cluster is possible (that is, it has one node from each node group) and it can't be in a network partitioned situation (that is, it has all of one node group), the cluster will perform a partial cluster restart, in which it starts up even though storage nodes are missing.
- If the cluster is in a potential network partitioned setup, where it doesn't have all of a single node group, then it will wait even longer, with a setting called StartPartitionedTimeout, which defaults to 60 seconds.
- Adding databases propagates to all SQL nodes (at least with the latest version of MySQL), so when you create a new database, you only need to do it once on any SQL node. However, users dont propagate, so each SQL node will need to have its own users set up. Warning: do NOT try to change the MySQL internal tables (the ones in database mysql) to type ndbcluster as the cluster will break.
- I will think of something else to put here.
Notes
My Setup
This is my sample configuration with sample IPs:
- mysql-5.1.22-rc-linux-i686-icc-glibc23
- 1x management node (OpenSUSE): 10.0.0.1
- 4x storage (ndbd) nodes (OpenSUSE): 10.0.0.2, 10.0.0.3, 10.0.0.4, 10.0.0.5.
- 4x query (SQL) nodes (OpenSUSE): 10.0.0.2, 10.0.0.3, 10.0.0.4, 10.0.0.5.
- NoOfReplicas = 2, meaning there will be 2 copies of all data and therefore 4/2=2 node groups.
- Cluster data will sit in /var/lib/mysql-cluster.
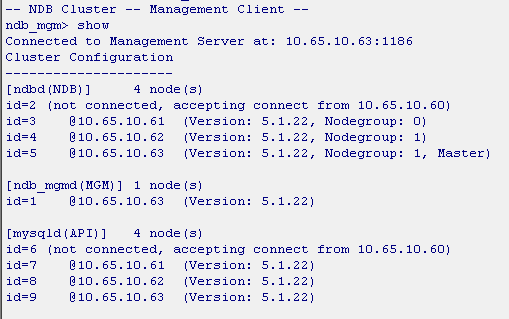
Sample Screenshot
Here is a sample screenshot of another one of my configurations showing a similar setup. This is the output of show on the management node:
Setup Instructions
On the management node (as root):
1 2 3 4 5 6 7 | groupadd mysql
useradd -g mysql mysql
mkdir -p /root/src/
cd /root/src/
wget http://dev.mysql.com/get/Downloads/MySQL-5.1/mysql-5.1.22-rc-linux-i686-icc-glibc23.tar.gz/from/http://mysql.he.net/
tar xvzf mysql-*.tar.gz
rm mysql-*.tar.gz |
- ndb_mgmd is the management server
- ndb_mgm is the management client
1 2 3 4 5 | cp mysql-*/bin/ndb_mg* /usr/bin/ chmod +x /usr/bin/ndb_mg* mkdir /var/lib/mysql-cluster chown mysql:mysql /var/lib/mysql-cluster vi /var/lib/mysql-cluster/config.ini |
Download /var/lib/mysql-cluster/config.ini
1 2 3 | ndb_mgmd -f /var/lib/mysql-cluster/config.ini ndb_mgm show |
On each storage and SQL node (as root):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | groupadd mysql
useradd -g mysql mysql
cd /usr/local
wget http://dev.mysql.com/get/Downloads/MySQL-5.1/mysql-5.1.22-rc-linux-i686-icc-glibc23.tar.gz/from/http://mysql.he.net/
tar xvzf mysql-*.tar.gz
rm mysql-*.tar.gz
ln -s `echo mysql-*` mysql
cd mysql
chown -R root .
chown -R mysql data
chgrp -R mysql .
scripts/mysql_install_db --user=mysql
cp support-files/mysql.server /etc/init.d/
chmod +x /etc/init.d/mysql.server
vi /etc/my.cnf |
Download /etc/my.cnf
1 2 3 4 5 6 7 8 9 | mkdir /var/lib/mysql-cluster chown mysql:mysql /var/lib/mysql-cluster cd /var/lib/mysql-cluster su mysql /usr/local/mysql/bin/ndbd --initial # start the storage node and force it to (re)read the config exit echo "/usr/local/mysql/bin/ndbd" > /etc/init.d/ndbd chmod +x /etc/init.d/ndbd /etc/init.d/mysql.server restart # start the query node |
SUSE:
1 2 3 4 | chkconfig --add mysql.server # this is SUSE's way of starting applications on system boot chkconfig --add ndbd chkconfig --list mysql.server chkconfig --list ndbd |
Ubuntu:
1 2 3 4 5 | sudo apt-get install sysv-rc-conf # this is chkconfig's equivalent in Ubuntu sysv-rc-conf mysql.server on sysv-rc-conf ndbd on sysv-rc-conf --list mysql.server sysv-rc-conf --list ndbd |
That's it! At this point you should go back to the management console that you logged into earlier (ndb_mgm) and issue the 'show' command again. If everything is fine, you should see your data and SQL nodes connected. Now you can login to any SQL node, make some users, and create new ndb tables. If you're experiencing problems, do leave a message in the comments.
In the next mysql cluster article, I will explore various cluster error messages I have encountered as well as config file tweaking. Now go and spend some time outside in the sun – life is too short to waste it at a dark office.
In the meantime, if you found this article useful, feel free to buy me a cup of coffee below.

