MySQL Conference Liveblogging: Performance Guide For MySQL Cluster (Tuesday 10:50AM)
- Speaker: Mikael Ronstrom, PhD, the creator of the Cluster engine
- Explains the cluster structure
- Aspects of performance
- Response times
- Throughput
- Low variation of response times
- Improving performance
- use low level API (NDB API), expensive, hard
- use new features in MySQL Cluster Carrier Grade Edition 6.3 (currently 6.3.13), more on this later
- proper partitioning of tables, minimize communication
- use of hardware
- NDB API is a C++ record access API
- supports sending parallel record operations within the same transaction or in different transactions
- asynchronous and synchronous
- NDB kernel is programmed entirely asynchronously
- Looking at performance
- Fire synchronous insert transactions – 10x TCP/IP time cost
- Five inserts in one synchronous transaction – 2x TCP/IP time cost
- Five asynchronous insert transactions – 2x TCP/IP
…
My MySQL Conference Schedule
Were there too many "my"'s in that title? Anyway… this week's MySQL conference is promising to be really busy and exciting. I can't wait to finally be there and experience it in all its glory. Thanks to the O'Reilly personal conference planner and scheduler and the advice of my fellow conference goers, I was able to easily (not really) pick out the speeches I am most interested in attending.
Here goes (my pass doesn't include Monday 🙁 ):
Tuesday
8:30am Tuesday, 04/15/2008
Keynote Ballroom E
Mårten Mickos (MySQL)
In his annual State of MySQL keynote, Marten discusses the current and future role of MySQL in the modern online world. The presentation also covers the …
Updated: April 23rd, 2008
[WORK IN PROGRESS] Here is a list of commands that I use every day with vim, in no particular order. Out of a billion possible key combinations, I found these to be irreplaceable and simple enough to remember.
|
* |
search for the word under cursor (to the end of the file) |
|
# |
search for the word under cursor (to the top of the file) |
|
ctrl-p,ctrl-n |
suggest (p)revious or (n)ext autocomplete from the list of existing keywords in the file or included files (!). |
|
:go NNN |
go to byte NNN |
|
. |
redo last command |
|
/SEARCH TERM |
search document for SEARCH TERM |
|
:%s/FOO/BAR/gci |
replace FOO with BAR (g)lobally, case (i)insensitively, and asking for (c)onfirmation |
…
Tax Season – How To Properly Import Trades From Scottrade And InteractiveBrokers
Updated: July 30th, 2021
Why do I dread doing taxes every year? One of the main reason was having to figure out ways to import hundreds of transactions from my stock brokers: Scottrade and InteractiveBrokers. I love IB but come on, it's 2008 and they still don't provide .txf files to import into TurboTax (or TaxCut, but I use TurboTax myself). Scottrade, on the other hand, is directly importable through TurboTax but it only imports sale amounts and not purchases, so TurboTax thinks I got my stocks for free and wants to tax me on the full sale amount rather than the profits. That is, of course, very incorrect. Here are the best solutions I could find to these problems:
1. Scottrade….
Updated: July 8th, 2009
Today I was asked a question about defining custom extensions for vim syntax highlighting such that, for example, vim would know that example.lmx is actually of type xml and apply xml syntax highlighting to it. I know vim already automatically does it not just based on extension but by looking for certain strings inside the text, like <?xml but what if my file doesn't have such strings?

After digging around I found the solution. Add the following to ~/.vimrc (the vim configuration file):
1 2 3 |
syntax on filetype on au BufNewFile,BufRead *.lmx set filetype=xml |
After applying it, my .lmx file is highlighted:

Same principle works, for instance, for mysql dumps …
Parsing JSON In Perl By Example – SouthParkStudios.com South Park Episodes
Updated: May 23rd, 2009
In this tutorial, I'll show you how to parse JSON using Perl. As a fun example, I'll use the new SouthParkStudios.com site released earlier this week, which contains full legal episodes of South Park. I guess the TV companies are finally getting a clue about what users want.
I will parse the first season's JSON and pull out information about individual episodes (like title, description, air date, etc) from http://www.southparkstudios.com/includes/utils/proxy_feed.php?html=season_json.jhtml%3fseason=1. Feel free to replace '1' with any valid season number.
Here's a short snippet of the JSON:
As half of the world population already knows, the MySQL conference is coming in less than 3 weeks. Since this event only happens once a year, lasts only 4 days, and costs more than a Russian mail-order bride, I'd really like to get the most out of it. Considering that the schedule is completely packed, with 8 (!!) events going on in parallel, I imagine things can get a little frantic. Additionally, I've never been to a conference of such size before and I'm not sure what to expect.
So… I'm contemplating:
Updated: January 4th, 2009
Here are some quick links for now: http://blogs.mysql.com/kaj/2008/05/23/mysql-clusters-improved-release-model/, http://johanandersson.blogspot.com/2008/05/mysql-cluster-62-officially-released.html, http://blogs.sun.com/theaquarium/entry/improved_release_model_for_mysql.
This article contains my notes and detailed instructions on setting up a MySQL cluster. After reading it, you should have a good understanding of what a MySQL cluster is capable of, how and why it works, and how to set one of these bad boys up. Note that I'm primarily a developer, with an interest in systems administration but I think that every developer should be able to understand and set up a MySQL cluster, at least to …
MySQL Conference 2008
Updated: March 26th, 2008
April 14-17th is going to be an exciting time. Why? Because the 2008 MySQL Conference and Expo is going to be held in Santa Clara, CA. Who would want to miss out on a chance to lurk around, let alone talk to, some of the smartest people in the MySQL world? Well, those who don't have at least $1000+, of course. A 3 day pass to the conference without tutorials costs a whopping $1199. A full pass would dry up your pockets $1499.
Well, "good news everyone". Thanks to Sheeri Cabral of The Pythian Group, PlanetMySQL.org, Jeremy, and, most importantly, LinuxQuestions.org, I am now in possession of a 3-day conference pass!! I'm incredibly excited that I …
How To Delete All Messages From A Folder In Pine
Pine is a UNIX command line mail application. So how do you delete all messages in a folder?
The combination is
1 |
; A A D |
If after pressing ; you see
1 |
[Command ";" not defined for this screen. Use ? for help] |
then you don't have a check in the "Enable aggregate command set" settings checkbox. To enable it, go to the main menu (M) -> Setup (S) -> Config (C) and scroll down to "Enable aggregate command set". Then press X (to check it), E (Exit). Now repeat the above….
Quick Perl Snippet: Finding If A File Has A Media Extension Using Regex
Updated: May 1st, 2008
Sometimes in my line of work, I need to figure out if a url or filename point to a media file by checking for the file extension. If it's a url, however, it may be followed by various parameters. Not to overcomplicate things, I came up with the following Perl code:
1 2 3 4 5 6 7 8 9 10 |
#!/usr/bin/perl -w use strict; my $name = "some_file.flv"; # or http://example.com/file.mp4?foo=bar my $is_media_type = ($name =~ /\.(wmv|avi|flv|mov|mkv|mp..?|swf|ra.?|rm|as.|m4[av]|smi.?)\b/i); if($is_media_type){ print "media extension found\n"; } else{ print "not a media file\n"; } |
…
Must-Know People In The MySQL Field
Updated: June 24th, 2020
If you're serious about MySQL, it doesn't hurt to know the people closely tied to its development and maintenance as well as famous bloggers. Here's my ongoing list of people I consider important:
 Peter Zaitsev – MySQL Performance Blog, former head of MySQL AB High Performance Group. His company Percona is available for consulting. He's a co-author of High Performance MySQL 2nd edition (great book).
Peter Zaitsev – MySQL Performance Blog, former head of MySQL AB High Performance Group. His company Percona is available for consulting. He's a co-author of High Performance MySQL 2nd edition (great book).
Baron Schwartz – also known as Xaprb, Baron a co-author of High Performance MySQL 2nd edition and creator of innotop and Maatkit. Maatkit is simply brilliant, and so is Baron. Baron recently joined Peter Zaitsev at Percona.
 Jeremy Zawodny – MySQL guru, works for Yahoo, and is considered a legend. He wrote mytop…
Jeremy Zawodny – MySQL guru, works for Yahoo, and is considered a legend. He wrote mytop…
Programming Comic: Lisp, Perl, And God
Computer Science majors out there that went through tedious hours of studying Lisp – this is for you from xkcd. If you know Perl, it will make even more sense.

Source: http://xkcd.com/224/
See Also: Best Programming Comic Ever: Code Quality In WTFs/Minute…
Today Travis was messing around with a Chinese site blinkx has indexed a short while ago http://www.tudou.com and saw a cryptic error message that started coming up on all pages. The message looked something like this:

各位土豆:
为了给大家提供更好的服务,我们正在搬迁扩建土豆的中心机房。
3月14日凌晨0:00 ~ 夜间24:00,我们的服务暂停24小时。
3月15日凌晨0:00 新机房就搬迁完成了,土豆会准时回家。
Now, neither Travis nor I know the language of Chinese, so what do we do? Go to Google Translate, of course. Here's what Google Translate produced:
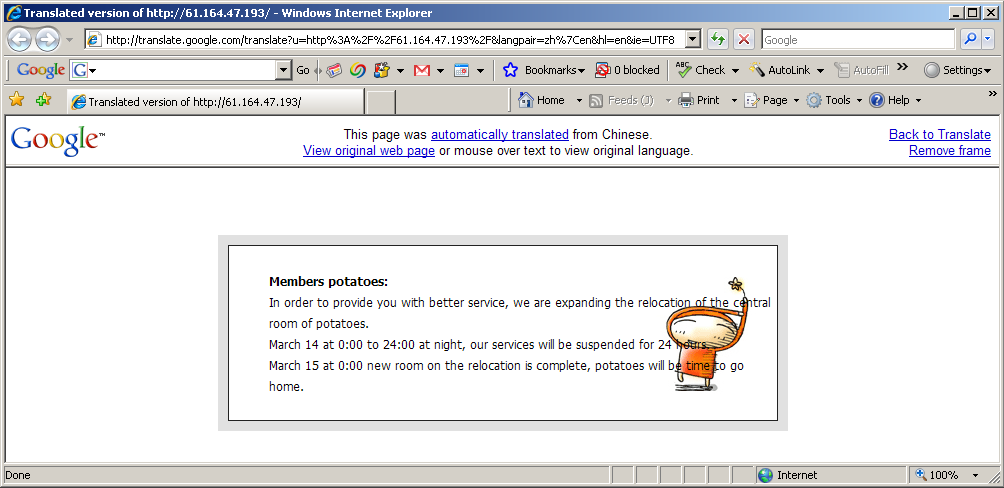
That's:
Members potatoes:
In order to provide you with better service, we are expanding the relocation of the central room of potatoes.
March 14 at 0:00 to 24:00 at night, our services will be suspended for 24 hours.
March 15 at 0:00 new room on the relocation is …
Mass Renaming Directories And Files Using Total Commander
Updated: September 16th, 2012
If you're like me, you constantly move and rename files and directories. You are also an extremely productive person with evangelical ideals of making every task as efficient as it can be. In this tutorial, I will use my favorite must-have file manager called Total Commander (formerly, Windows Commander) and its brilliant Multi-Rename Tool.
You can download a shareware version of Total Commander at www.ghisler.com. I encourage you to buy it after you try it as it'll soon become an integral part of your life. I've been using it for more than 10 years now and seriously can't imagine my computer without it.
Now for some quick tasks I'd like to accomplish using the Multi-Rename Tool in under a …

