Updated: July 30th, 2021
The Problem
I am throwing up a quick post about a relatively cryptic error that Solr started throwing the other day here at Plaxo. After happily running for a few days, I suddenly started getting pages about failed Solr indexing.
Upon closer examination, I saw the following repeatedly in the log file:
catalina.2009-09-18.log:SEVERE: java.io.IOException: directory 'DATADIR/index' exists and is a directory, but cannot be listed: list() returned null |
I tried to see if sending an OPTIMIZE command would help but the server returned the same response.
Digging Deeper
The reason was these errors was quite simple – Solr was running …
Do NOT Use This Perl Module: Passwd::Unix
Updated: April 29th, 2008
Update: The author of the module contacted me the same day and promised to fix it in the next version. Version 0.40 was indeed on cpan as promised, but I haven't tested it yet.
Passwd::Unix will corrupt your /etc/shadow file and rearrange login names and their corresponding password hashes.
The current version of Passwd::Unix corrupted my /etc/shadow upon only
calling the passwd() function. Immediately users started to report not
being able to login.
After examining the situation, I found that Passwd::Unix rearranges all
users in /etc/shadow in some way, but it only does it to the
usernames, and not the password hashes. Thus, you will get corrupted accounts. Moreover,
users are now able to login to one OTHER account, not …
Updated: January 4th, 2009
Here are some quick links for now: http://blogs.mysql.com/kaj/2008/05/23/mysql-clusters-improved-release-model/, http://johanandersson.blogspot.com/2008/05/mysql-cluster-62-officially-released.html, http://blogs.sun.com/theaquarium/entry/improved_release_model_for_mysql.
This article contains my notes and detailed instructions on setting up a MySQL cluster. After reading it, you should have a good understanding of what a MySQL cluster is capable of, how and why it works, and how to set one of these bad boys up. Note that I'm primarily a developer, with an interest in systems administration but I think that every developer should be able to understand and set up a MySQL cluster, at least to …
MySQL Conference 2008
Updated: March 26th, 2008
April 14-17th is going to be an exciting time. Why? Because the 2008 MySQL Conference and Expo is going to be held in Santa Clara, CA. Who would want to miss out on a chance to lurk around, let alone talk to, some of the smartest people in the MySQL world? Well, those who don't have at least $1000+, of course. A 3 day pass to the conference without tutorials costs a whopping $1199. A full pass would dry up your pockets $1499.
Well, "good news everyone". Thanks to Sheeri Cabral of The Pythian Group, PlanetMySQL.org, Jeremy, and, most importantly, LinuxQuestions.org, I am now in possession of a 3-day conference pass!! I'm incredibly excited that I …
How To Delete All Messages From A Folder In Pine
Pine is a UNIX command line mail application. So how do you delete all messages in a folder?
The combination is
1 |
; A A D |
If after pressing ; you see
1 |
[Command ";" not defined for this screen. Use ? for help] |
then you don't have a check in the "Enable aggregate command set" settings checkbox. To enable it, go to the main menu (M) -> Setup (S) -> Config (C) and scroll down to "Enable aggregate command set". Then press X (to check it), E (Exit). Now repeat the above….
Make Screen and YaST Work Together
Updated: March 19th, 2008
I don't know about you but I've had a lot of problems making screen work nicely with YaST. Both putty and SecureCRT had major problems displaying YaST's ncurses interface. The screenshots below depict the problem quite clearly. If at this point you don't see anything like this, you are most likely not affected and can go get a beer.
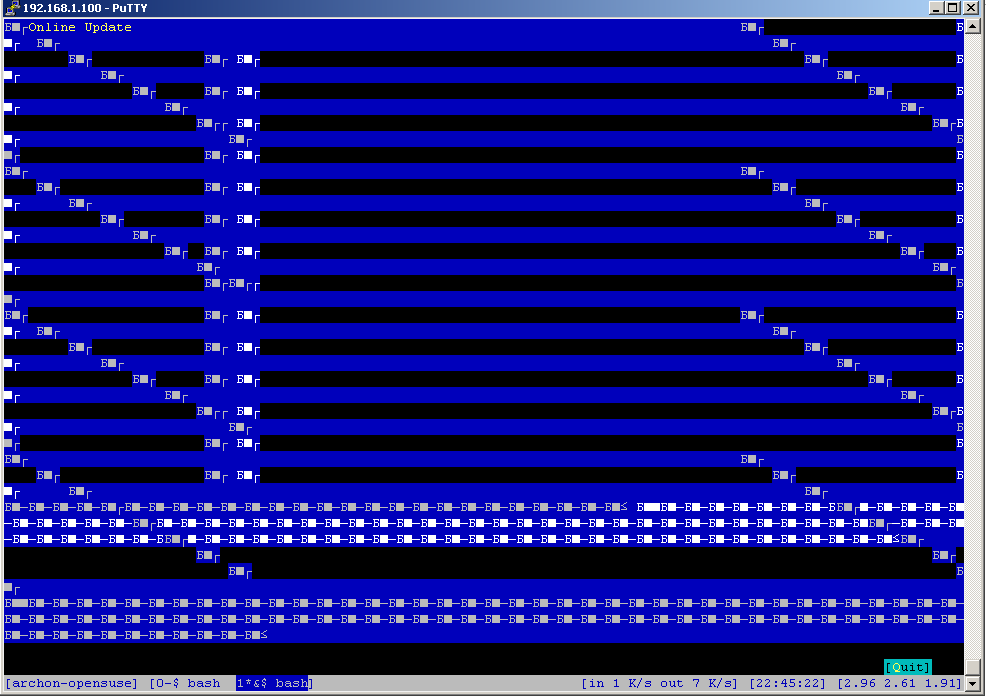
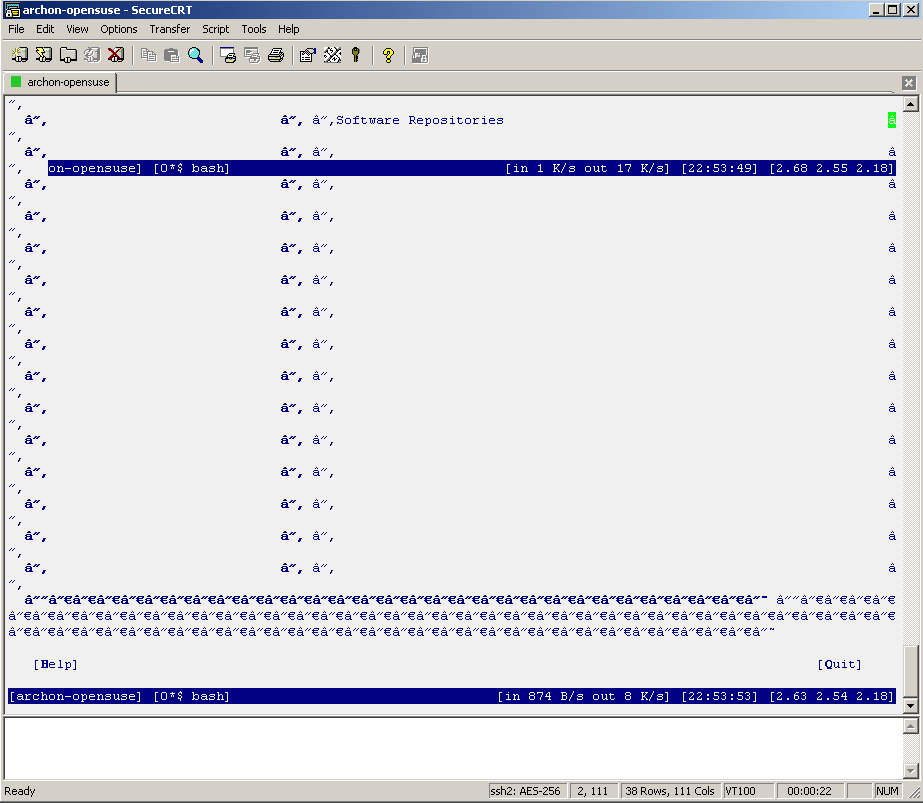
If you are seeing similar problems, here's the fix. After digging around a bit, I have discovered that the problem was incorrect data encoding. My character set was set to KOI8-R while ncurses expected UTF-8. Here is how to change the corresponding setting in putty:
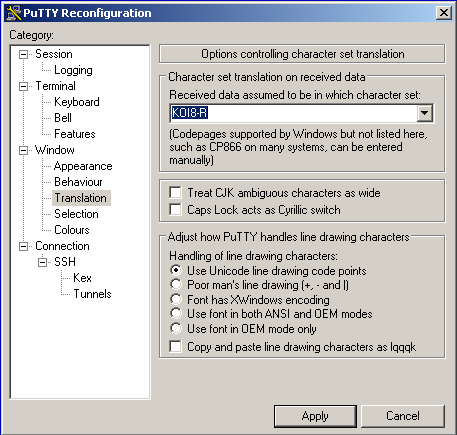
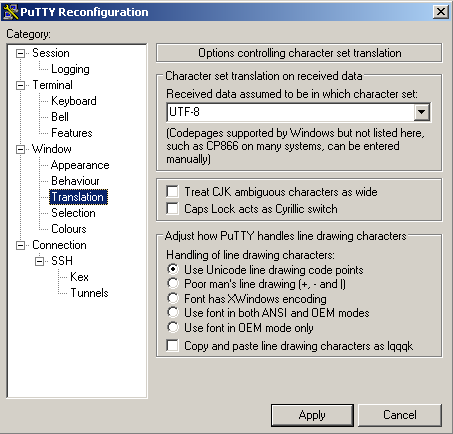
… and SecureCRT:
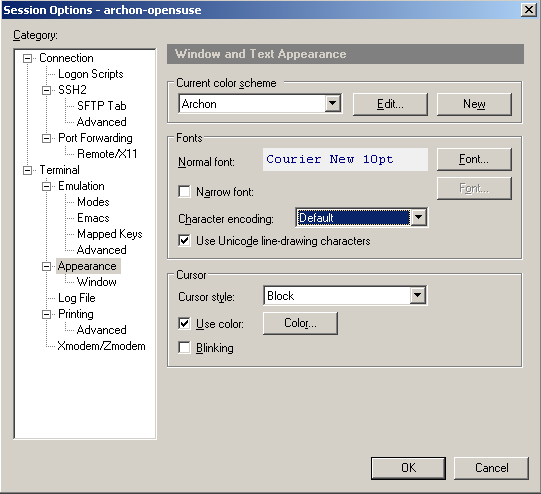
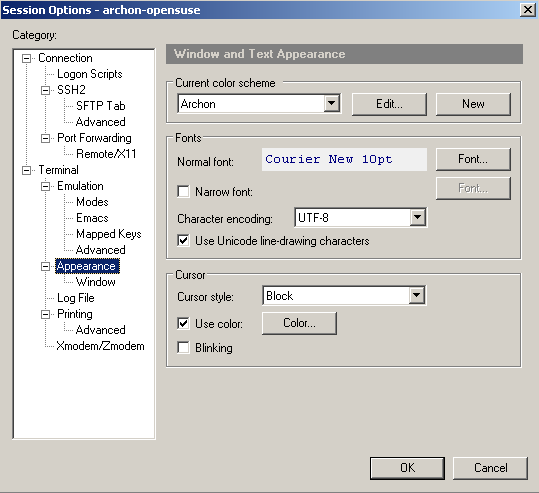
Now restart YaST and voila:
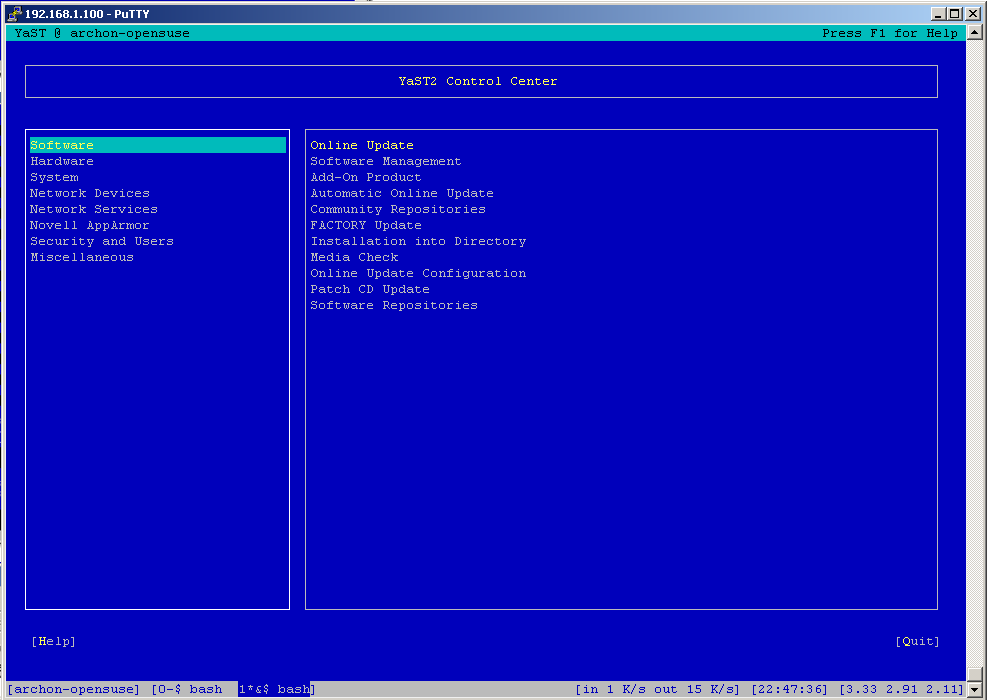
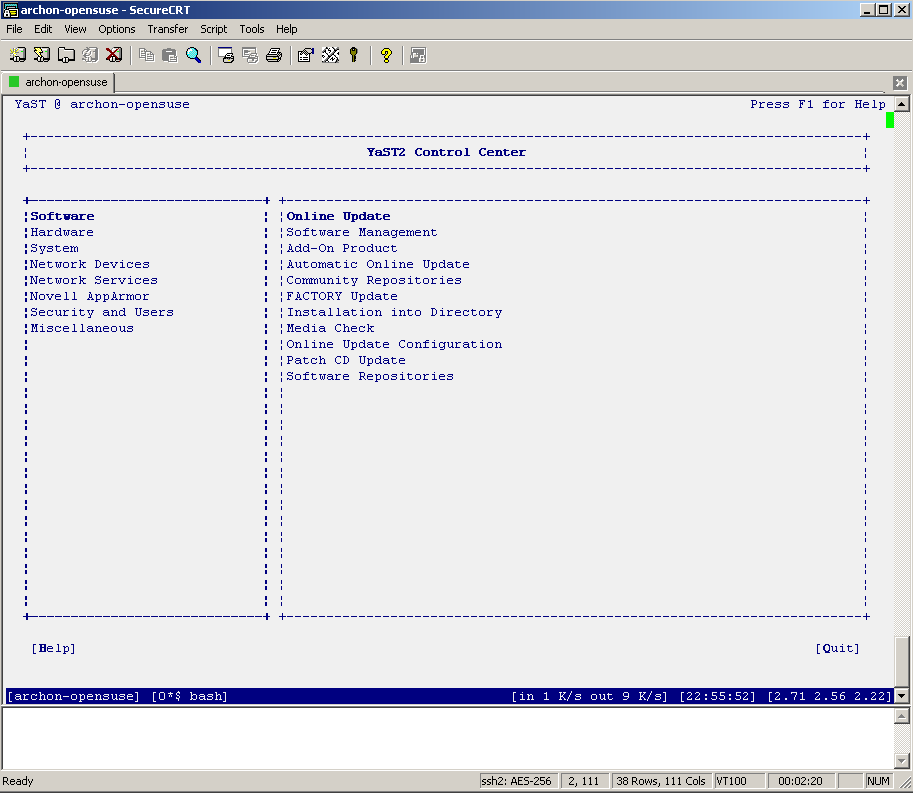
P.S. You may be wondering why my screen …
cpan – The Perl Module Manager
Updated: March 19th, 2008
cpan is a perl module manager. To get into cpan, login as root and type in
cpan |
Install a module:
cpan install MODULE |
Upgrade a module:
cpan upgrade MODULE |
Reinstall a module or force install in case of failed tests:
force install MODULE |
See a list of upgradable modules:
r |
See cpan configuration (that's the letter 'o'):
o conf |
Update an option in cpan configuration:
o conf OPTION_NAME OPTION_VALUE |
It is always nice to:
upgrade CPAN install Bundle::CPAN |
If there's an error making a Perl module, it can be caused by a missing make path in cpan configuration. In …
Updated: October 22nd, 2011
sysbench – Linux test bench. Easy as pie to test CPU, memory, threads, mysql, and disk performance.
Full description is available here: http://sysbench.sourceforge.net/docs/
install mysql, mysql-devel wget http://downloads.sourceforge.net/project/sysbench/sysbench/0.4.12/sysbench-0.4.12.tar.gz tar xvzf sysbench*gz cd sysbench* ./configure && make install |
mysql tests
This will run 10 separate consecutive mysql tests using an InnoDB table type, each with 100 mysql threads, doing a total of 1000 various SQL operations per test. Then it will print the total time they took to finish:
Watch – A Useful Linux Command You May Have Never Heard Of
Updated: November 9th, 2007
How many times did I want to watch a directory waiting for a file to appear in it? Constant ls, for example, quickly got boring. A quick Perl script that would reload ls every 5 seconds… yeah it works but it takes a while to type up, and often enough I'm too lazy for that. And then I found 'watch' – a utility that comes with most *nix distros. Look at this beauty [man watch]:
NAME
watch – execute a program periodically, showing output fullscreen
SYNOPSIS
watch [-dhvt] [-n ] [–differences[=cumulative]] [–help]
[–interval=] [–no-title] [–version]
DESCRIPTION
watch runs command repeatedly, displaying its output (the first screen
full). This allows you to watch the program output change over time.
By default, …
Updated: November 9th, 2007
So today I was looking for a proper sources.list file that would work for apt-get in SUSE 10.2 since the one in yast and smart repositories comes with a broken list. And by broken I mean completely f***ed.
apt-get update Err ftp://mirrors.mathematik.uni-bielefeld.de SuSE/10.2-i386 release Could not resolve 'mirrors.mathematik.uni-bielefeld.de' Get:1 ftp://ftp4.gwdg.de SuSE/10.2-i386 release Ign ftp://ftp4.gwdg.de SuSE/10.2-i386 release Err ftp://mirrors.mathematik.uni-bielefeld.de SuSE/10.2-i386/base pkglist Could not resolve 'mirrors.mathematik.uni-bielefeld.de' Err ftp://mirrors.mathematik.uni-bielefeld.de SuSE/10.2-i386/base release Could not resolve 'mirrors.mathematik.uni-bielefeld.de' Err ftp://mirrors.mathematik.uni-bielefeld.de SuSE/10.2-i386/update pkglist Could not resolve 'mirrors.mathematik.uni-bielefeld.de' Get:1 ftp://ftp4.gwdg.de SuSE/10.2-i386/base pkglist Err ftp://mirrors.mathematik.uni-bielefeld.de SuSE/10.2-i386/update release Could not resolve 'mirrors.mathematik.uni-bielefeld.de' Err ftp://ftp4.gwdg.de SuSE/10.2-i386/base pkglist Unable to fetch file, |
…
Linux openSUSE 10.2 Learning Experience #1: Introduction
Updated: June 24th, 2020
The purpose of this article is to:
- introduce the new Linux section of the site (specifically dedicated to openSUSE).
- provide a very short description of Linux and compare it to other operating systems.
- answer some installation questions.
I'm a Windows user, I admit it. Not because I enjoy frequent reboots, freezes, and other unexplainable quirks. It's mostly because I have so many programs I'm used to, it would be impossible to switch to anything else, and I know ins and outs that allow me to be very comfortable with the Windows. I'm talking 20-30 programs I'm not willing to give up any time soon.
 However, I also have deep respect for *nix based systems. I started using them back in …
However, I also have deep respect for *nix based systems. I started using them back in …
Updated: November 4th, 2007

Installed Ubuntu LTS 6.06 as a 2nd OS on my Dell E1505 laptop today after delaying doing this for a while. This article from digg finally made me install it, which took roughly 10 minutes, as it mentions. Compare this and 0 reboots to 45min and 5 reboots installing Windows. Ubuntu's pretty damn sweet; I'm gonna go tweak it now with the help of Arthur. I'm predicting that Linux (and Ubuntu in particular, as of now) will eat up Windows' market share surely and quickly. The dual boot is very friendly, it uses GRUB as the boot manager. To boot directly into Windows by default, I edited /boot/grub/menu.list from Ubuntu….

